Check out a groundbreaking paper on improving text embeddings with large language models (LLMs) like GPT-4! The authors propose generating synthetic training data for text embedding tasks using LLMs, instead of relying on human-labeled datasets.
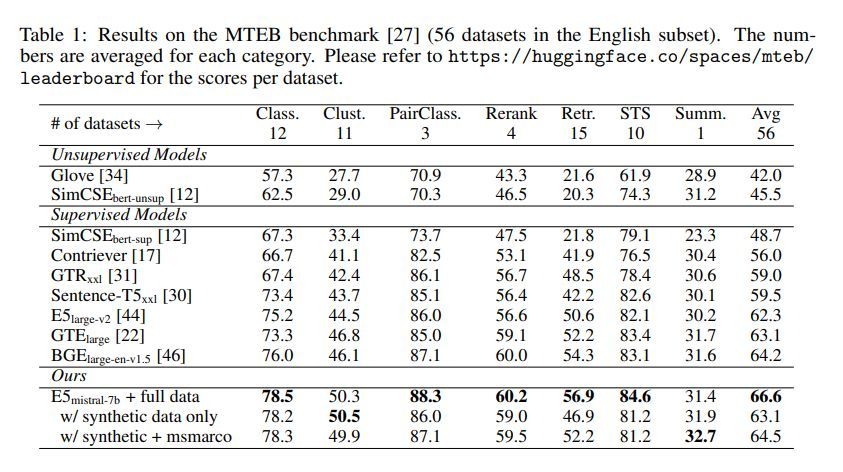
Their two-step prompt method generates diverse synthetic data for hundreds of thousands of embedding tasks across 93 languages, covering semantic textual similarity, bitext retrieval, and more. The Mistral-7B LLM is fine-tuned on the synthetic data and achieves state-of-the-art results on the MTEB benchmark, outperforming previous models by 2.4 points on average across task categories.
In summary, this paper presents an effective and efficient method for improving text embeddings by leveraging data generation with LLMs.